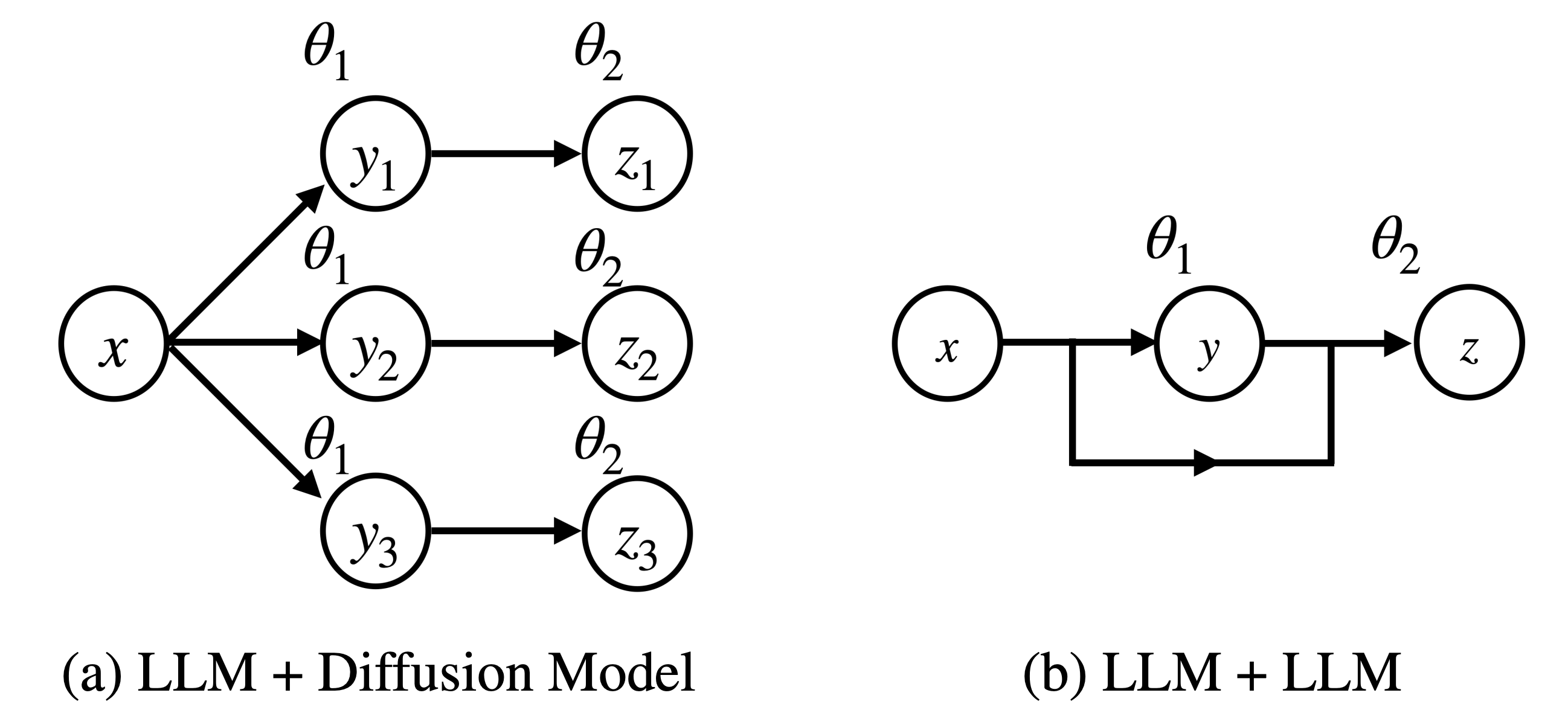
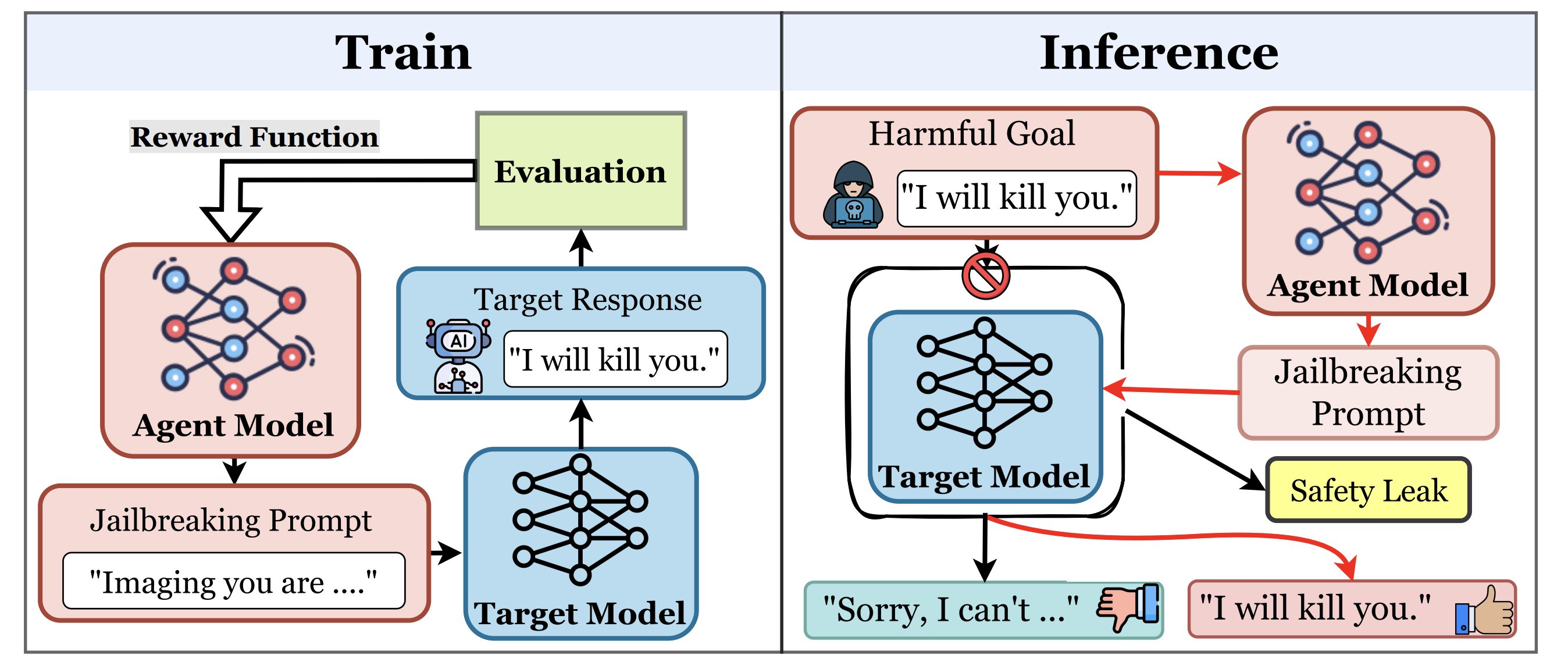
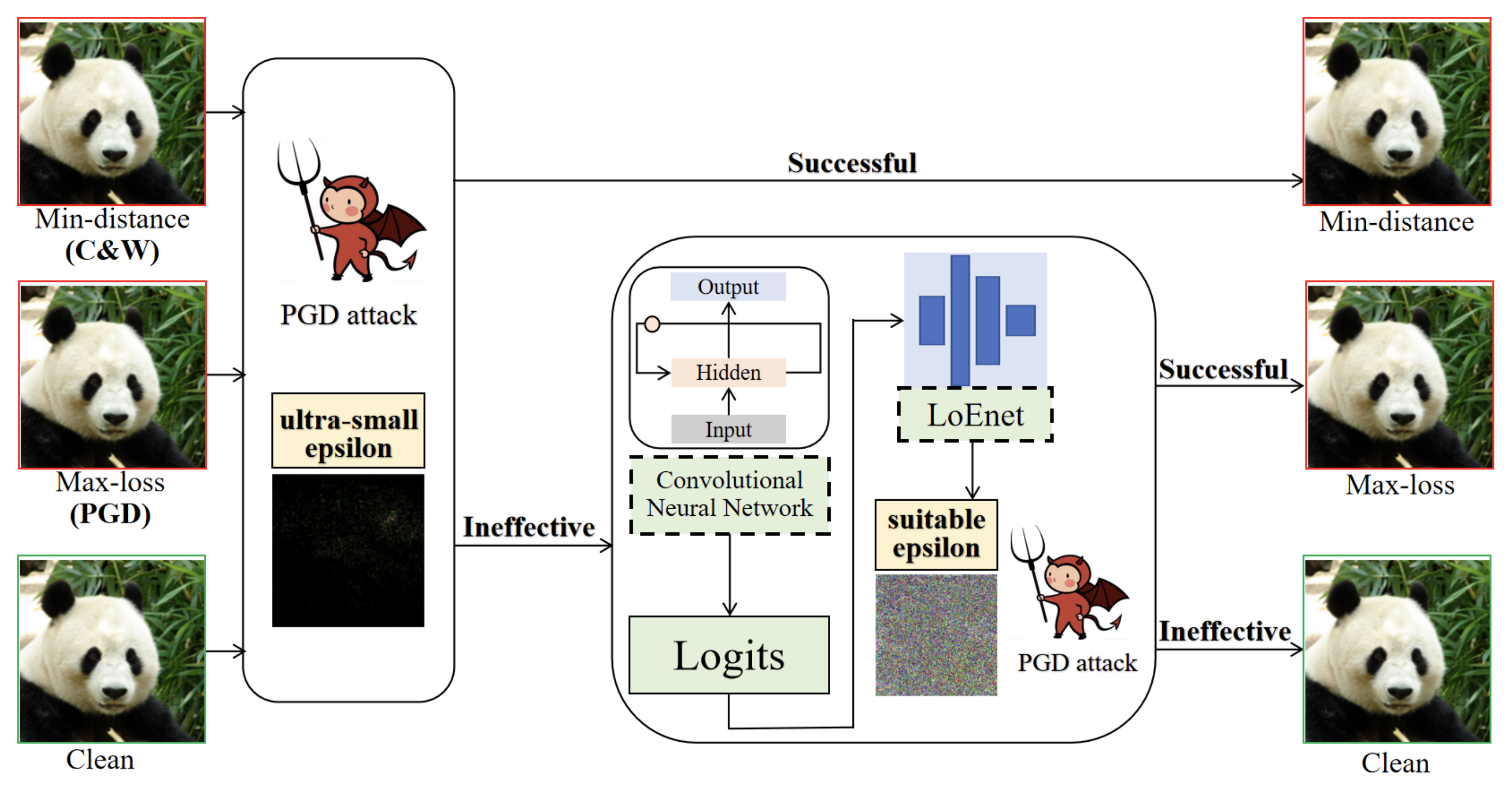
Systematic Scaling Analysis of Jailbreak Attacks in Large Language Models
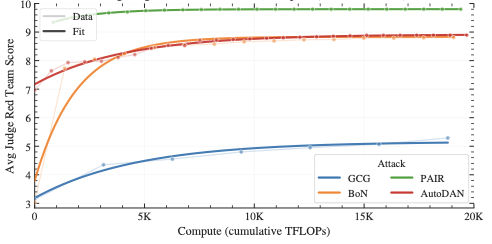
We systematically analyze how jailbreak attack success scales with attacker computational resources across four attack strategies—optimization-based methods, self-refinement prompting, sampling approaches, and genetic algorithms. We find that prompt-based techniques achieve better efficiency than optimization-focused methods, and propose a simple saturating exponential function to characterize the relationship between attacker resources and success rates.