
Xiangwen Wang
Hi! I’m Xiangwen Wang (王香雯), a first-year MSCS student at the University of Illinois Urbana–Champaign (UIUC), where I am fortunate to be advised by Professor Varun Chandrasekaran. I received my bachelor’s degree from the School of the Gifted Young, University of Science and Technology of China (USTC), and I also spent a summer as a research intern at STAIR Lab, Stanford University.
My research interests lie broadly in post-training for large language models and trustworthy AI, with a focus on AI alignment, LLM security, and the reliability of multi-component and multi-agent systems. My long-term goal is to build AI systems that are safe, robust, and value-aligned, especially as they scale into complex, real-world settings.
Research Interests
AI Alignment & Preference Learning
Aligning LLMs with human values, improving preference-optimization algorithms, and aligning compound systems.LLM Safety & Reliability
Jailbreak and backdoor attacks, red-teaming, post-training safety, and scalable evaluations.Multi-agent & Compound AI Systems
Studying interactions, coordination, and optimization in multi-agent or multi-component AI systems.
Publications
Systematic Scaling Analysis of Jailbreak Attacks in Large Language Models
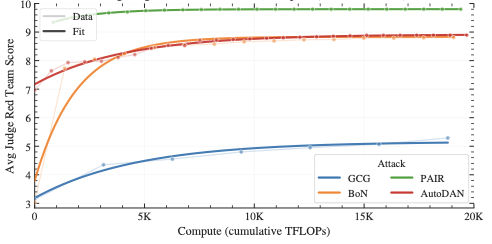
We systematically analyze how jailbreak attack success scales with attacker computational resources across four attack strategies—optimization-based methods, self-refinement prompting, sampling approaches, and genetic algorithms. We find that prompt-based techniques achieve better efficiency than optimization-focused methods, and propose a simple saturating exponential function to characterize the relationship between attacker resources and success rates.
Aligning Compound AI Systems via System-level DPO
Published in NeurIPS 2025
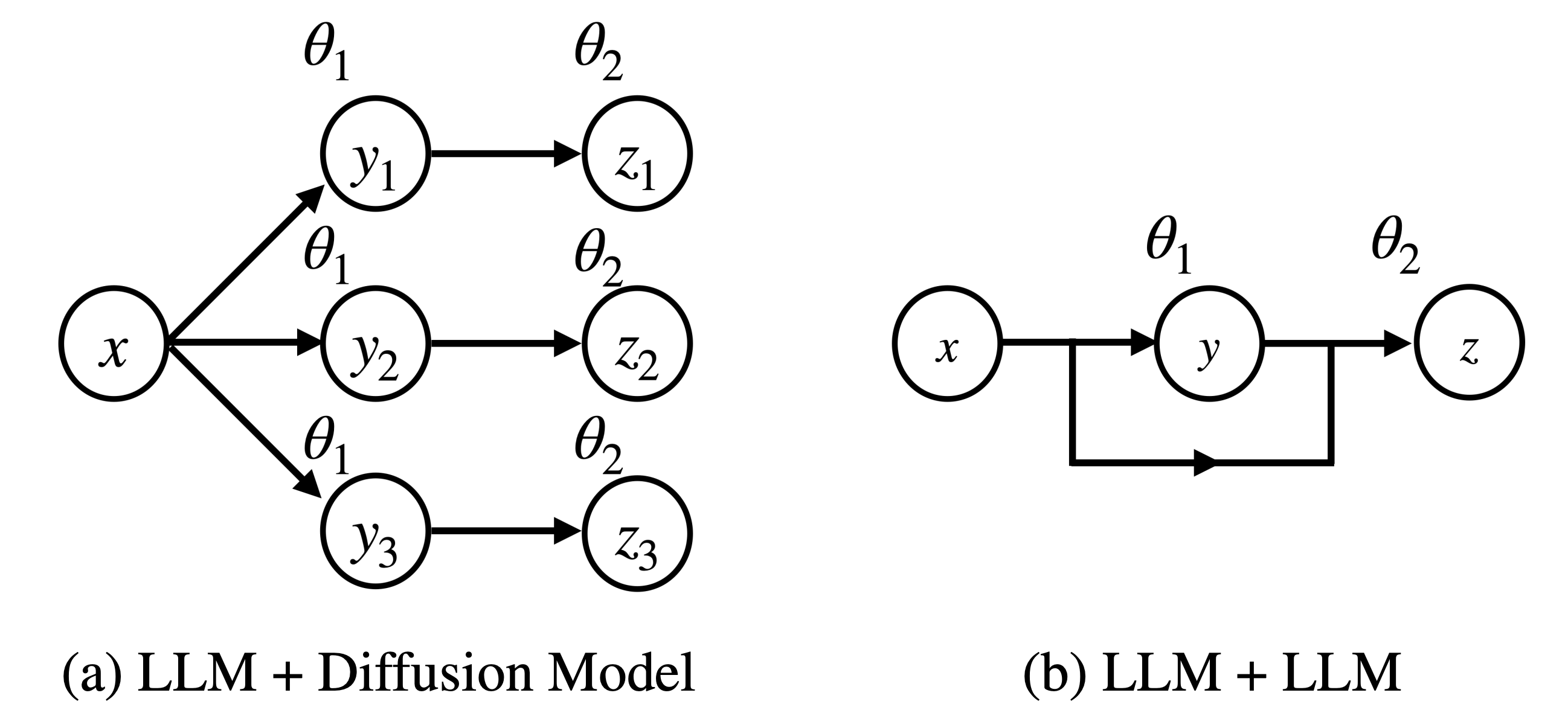
We propose SysDPO, the first framework for aligning compound AI systems at the system level. By modeling the system as a directed acyclic graph of components, SysDPO enables joint optimization even in the presence of non-differentiable links and missing component-level preferences. We demonstrate its effectiveness on two applications: a language-model–plus–diffusion pipeline and a multi-LLM collaboration system.
Reinforcement Learning-Driven LLM Agent for Automated Attacks on LLMs
Published in ACL 2024 Workshop on Privacy in NLP (Oral)
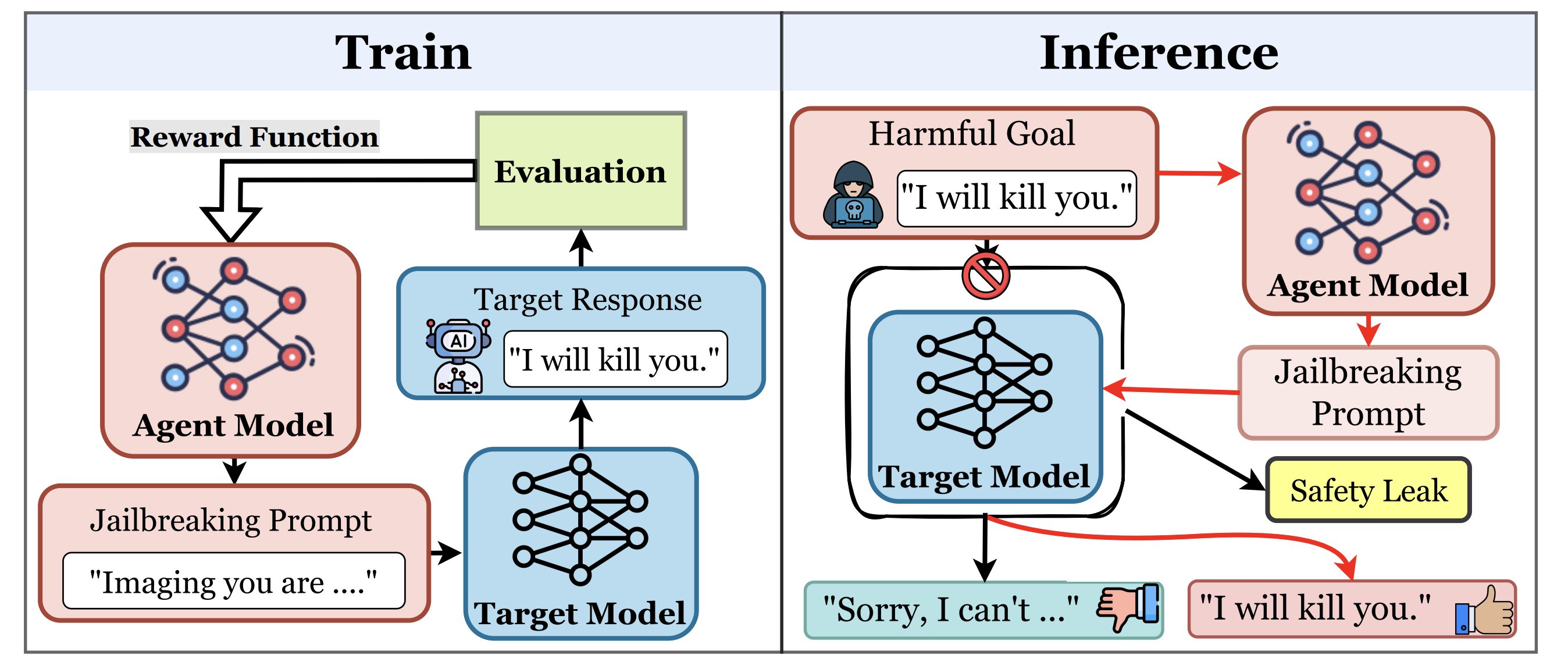
We design RLTA, a reinforcement learning-driven LLM agent for automated prompt-based attacks against target language models. RLTA explores and optimizes malicious prompts to increase attack success rates for both trojan detection and jailbreak tasks, outperforming baseline methods in black-box settings.
Adversarial Examples Detection Based on Adversarial Attack Sensitivity
Published in ICME 2025
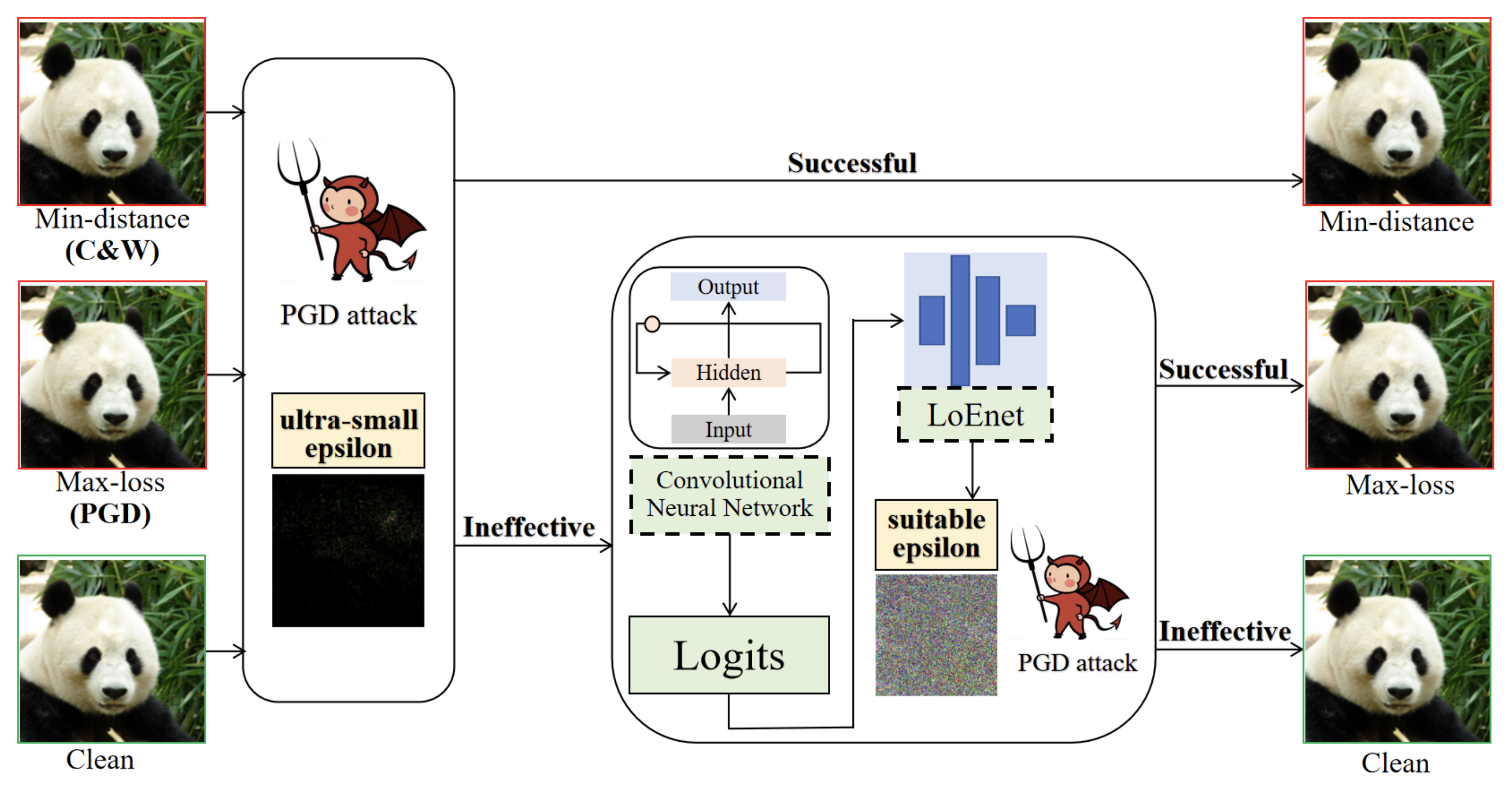
We propose ADAS, a detection method that exploits the sensitivity disparity between clean and adversarial samples under re-attacks. ADAS achieves strong robustness to minimal-perturbation attacks and shows good generalization to unseen adversarial methods across multiple datasets and architectures.